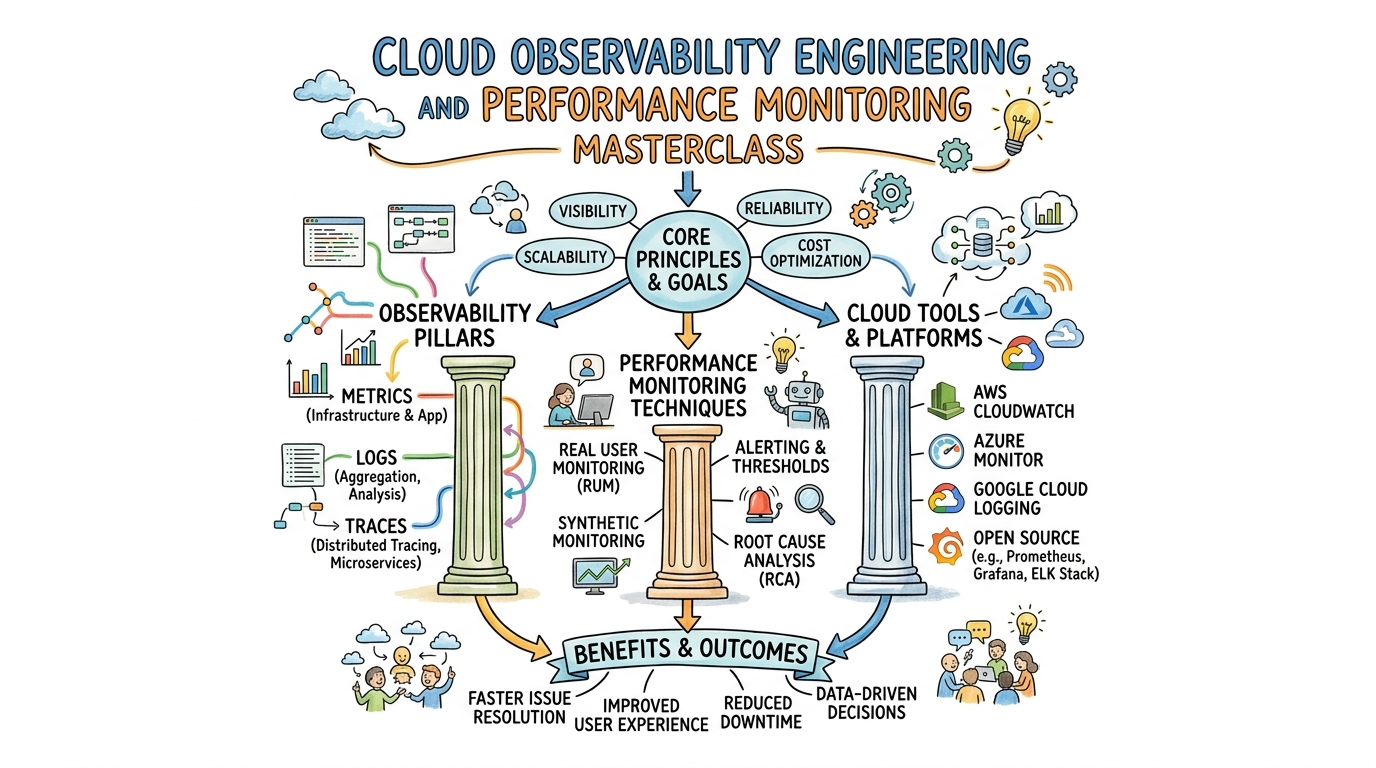
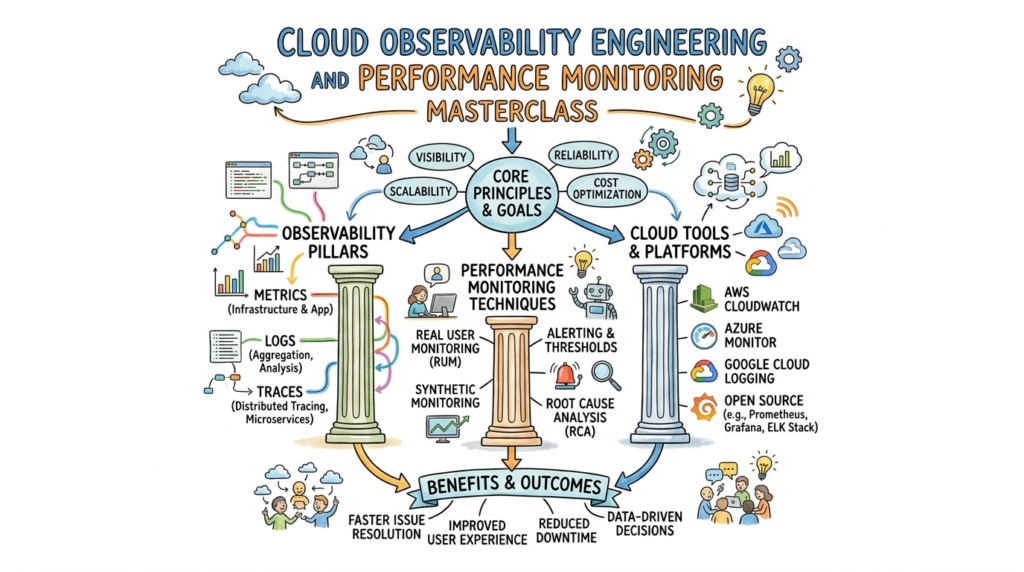
Introduction
In the complex landscape of modern distributed systems, the ability to understand the internal state of a system based on its external outputs is not just a skill—it is a requirement. This guide is designed for software engineers, site reliability engineers, and platform architects looking to Master in Observability Engineering. As systems transition toward microservices and cloud-native architectures, observability has become the cornerstone of incident response and performance tuning. This guide serves to provide clarity on how this certification fits into the broader [devopsschool] ecosystem, helping you navigate the transition from traditional monitoring to proactive observability. Whether you are aiming to [aiopsschool] your skill set or optimize complex infrastructure, understanding these principles is essential for long-term career growth in the industry.
What is the Master in Observability Engineering?
The Master in Observability Engineering represents a shift from reactive monitoring—where you simply watch for failure—to a proactive, data-driven understanding of system health. It covers the telemetry pillars of logs, metrics, and traces, ensuring that engineers can answer complex questions about system behavior in real-time. This program emphasizes real-world, production-focused learning, moving far beyond theoretical definitions to focus on implementation. It aligns with modern enterprise practices where minimizing mean time to detection (MTTD) and mean time to resolution (MTTR) are critical KPIs for engineering teams.
Who Should Pursue Master in Observability Engineering?
This certification is designed for professionals who manage, scale, or secure complex technical environments. It is highly recommended for site reliability engineers (SREs) who are responsible for uptime and performance, as well as DevOps engineers focused on building robust CI/CD pipelines. Security professionals will find immense value in using observability data to detect anomalies and potential breaches in real-time. Furthermore, engineering managers and technical leaders should pursue this knowledge to better architect systems for visibility from the ground up, ensuring that their teams can troubleshoot effectively in high-pressure production environments.
Why Master in Observability Engineering
As systems grow more fragmented and ephemeral, the traditional “dashboard-only” approach to monitoring is failing. Professionals who can master observability will remain highly relevant because they provide the “eyes” for the entire organization’s architecture. This certification helps engineers stay ahead of tool fatigue by teaching fundamental principles that apply regardless of whether you are using open-source stacks or proprietary cloud tools. The return on investment for this knowledge is high, as it directly impacts system reliability and reduces the burnout often associated with on-call shifts and persistent production outages.
Master in Observability Engineering Certification Overview
This certification program is delivered via the Master in Observability Engineering platform and hosted on [devopsschool]. The assessment approach is designed to be practical, requiring candidates to demonstrate knowledge through scenarios rather than rote memorization of documentation. It is structured to ensure that certified individuals possess the hands-on capability required to implement observability stacks in production environments. Certification ownership is recognized across the industry as a benchmark for technical competence in instrumentation, collection, and analysis.
Master in Observability Engineering Certification Tracks & Levels
The certification structure is divided into foundation, professional, and advanced tiers to accommodate different stages of career development. Foundation levels focus on the core pillars and basic tool configuration, while professional levels dive into architectural decisions and scaling telemetry data. Advanced levels are reserved for those designing organization-wide observability strategies and custom instrumentation pipelines. These tracks are mapped to align with career progression, ensuring that as you gain experience, the certification levels reflect your increasing ability to handle complex system observability at scale.
Complete Master in Observability Engineering Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Core | Foundation | Junior DevOps/SRE | Basic Linux/Cloud | Logs, Metrics, Traces | 1 |
| Advanced | Professional | Experienced Engineers | Foundation Cert | Distributed Tracing, Sampling | 2 |
| Strategy | Master | Tech Leads/Architects | Professional Cert | Observability at Scale | 3 |
Detailed Guide for Each Master in Observability Engineering Certification
Master in Observability Engineering – Foundation Level
What it is
This certification validates your fundamental understanding of telemetry, data collection, and the core pillars of observability.
Who should take it
Suitable for junior DevOps engineers, system administrators, and cloud engineers looking to build a strong baseline.
Skills you’ll gain
- Configuring log shippers and agents.
- Defining Golden Signals for services.
- Understanding metric aggregation and storage.
Real-world projects you should be able to do
- Set up a basic Prometheus and Grafana stack for a microservice.
- Configure log aggregation from a containerized application.
- Create standard dashboards for service health.
Preparation plan
- 7–14 days: Review the core pillars and basic instrumentation libraries.
- 30 days: Build three small projects using different data types.
- 60 days: Deep dive into the specific tool configurations taught in the course.
Common mistakes
Focusing too much on the tool and not enough on the underlying data concepts.
Best next certification after this
- Same-track: Professional level.
- Cross-track: Cloud Architecture.
- Leadership: Team Lead Fundamentals.
Choose Your Learning Path
DevOps Path
The DevOps path focuses on integrating observability into the CI/CD pipeline. You will learn to treat observability as code, ensuring that every deployment is automatically instrumented. This reduces the burden on operators and ensures that developers have immediate feedback loops after every release.
DevSecOps Path
The DevSecOps path emphasizes security observability, specifically using telemetry to identify unusual access patterns and potential exploits. This path is essential for those who need to maintain security posture while moving at high velocity.
SRE Path
The SRE path is about reliability and error budgets. You will learn how to use observability data to define and track Service Level Objectives (SLOs) and Service Level Indicators (SLIs). This is critical for managing system uptime.
AIOps Path
The AIOps path focuses on using machine learning to parse large volumes of telemetry data. You will learn to automate root cause analysis and event correlation to handle complex failure states.
MLOps Path
The MLOps path is dedicated to monitoring machine learning models in production. It covers model drift, data quality, and prediction latency, ensuring that models provide accurate and timely results.
DataOps Path
The DataOps path focuses on observing data pipelines. You will learn to monitor data quality, latency, and flow throughout the ETL process to ensure business-critical data remains reliable.
FinOps Path
The FinOps path explores observability in the context of cloud spend. You will learn to map resource utilization to cost metrics, identifying waste and optimizing infrastructure efficiency through data-driven decisions.
Role → Recommended Master in Observability Engineering Certifications
| Role | Recommended Certifications |
| DevOps Engineer | Foundation, Professional |
| SRE | Professional, Master |
| Platform Engineer | Professional, Master |
| Cloud Engineer | Foundation, Professional |
| Security Engineer | Professional |
| Data Engineer | Foundation |
| FinOps Practitioner | Professional |
| Engineering Manager | Master |
Next Certifications to Take After Master in Observability Engineering
Same Track Progression
Deepen your expertise by moving toward high-availability architecture and multi-cloud observability strategies. This involves mastering advanced sampling techniques and long-term storage optimization for telemetry data.
Cross-Track Expansion
Broaden your skill set by moving into security observability or cloud-native infrastructure automation. Understanding how these domains intersect with observability makes you a highly versatile engineer in any organization.
Leadership & Management Track
Transitioning to leadership involves moving from writing configuration files to designing observability strategies. Focus on building culture, defining SLOs, and aligning observability goals with business outcomes.
Training & Certification Support Providers for Master in Observability Engineering
DevOpsSchool
This provider is a leader in technical training, offering highly structured programs that focus on hands-on labs and real-world application of observability concepts.
Cotocus
Known for its specialized approach to enterprise-grade training, this organization helps teams bridge the gap between legacy systems and modern observability stacks.
Scmgalaxy
This institution focuses on the nuances of source code management and integrated monitoring, providing a comprehensive look at the DevOps toolchain ecosystem.
BestDevOps
Offering a platform for practitioners, this provider emphasizes peer-to-peer learning and practical workshops designed to solve common production engineering problems.
devsecopsschool
This dedicated entity specializes in the intersection of security and engineering, providing in-depth training on how to use observability for threat detection.
sreschool
An essential resource for SRE-focused learners, providing rigorous training on reliability engineering, error budgets, and incident management through observability.
aiopsschool
This school focuses on the future of operations, teaching how to integrate artificial intelligence into standard observability practices for automated incident resolution.
dataopsschool
Dedicated to data engineers, this provider ensures that data flow, quality, and pipeline reliability are maintained through robust monitoring practices.
finopsschool
Specializing in cost-management observability, this provider trains professionals to correlate infrastructure performance with actual cloud spending patterns.
Frequently Asked Questions (General)
- What is the primary difficulty level of this certification?
The program is designed to be challenging, requiring a balance of theoretical knowledge and practical execution to pass the assessments. - How much time is generally needed to complete this?
Most professionals find that with 10–15 hours of study per week, they can complete the certification within two months. - Are there any hard prerequisites before starting?
Basic proficiency in Linux and cloud infrastructure is highly recommended to get the most value out of the training. - Is this certification recognized by global enterprises?
Yes, the certification is widely respected as it focuses on vendor-neutral principles that apply to most modern tech stacks. - Does this certification offer hands-on lab environments?
The program prioritizes practical labs where students can deploy and manage their own observability stacks in a simulated production environment. - How does this improve my ROI in the job market?
Observability is a high-demand skill, and being certified demonstrates that you can reduce downtime and improve system efficiency. - Is there a specific sequence I should follow for these certifications?
It is best to start with the Foundation level to build your core understanding before moving to professional and master levels. - Can I take this certification if I am a manager?
Absolutely, the management track helps leaders understand the architectural requirements for building observable systems. - What is the format of the final assessment?
The assessment typically involves a mix of conceptual questions and a practical performance-based lab challenge. - How often is the curriculum updated?
The curriculum is regularly updated to reflect the latest advancements in open-source tooling and cloud-native observability standards. - Will this help me if I work in a legacy environment?
Yes, the core principles of observability are universal and can be applied to legacy systems to improve visibility. - Is there any post-certification community support?
Yes, graduates often gain access to alumni networks and forums for continuous learning and industry networking.
FAQs on Master in Observability Engineering
- What is the most important skill taught?The ability to instrument code for meaningful telemetry is the most critical skill for long-term success.
- Does this cover OpenTelemetry?Yes, the curriculum includes extensive training on OpenTelemetry as the industry-standard framework for observability.
- Is it vendor-specific?No, it focuses on universal principles that can be applied to any observability platform or cloud provider.
- How do I troubleshoot failed tests?You will learn to use trace data to identify bottlenecks and failure points in complex distributed systems.
- Is it heavy on programming?It requires an understanding of how code interacts with infrastructure, but deep coding is secondary to system architecture.
- Can I use this for cloud-cost analysis?The program covers how metrics can be used to monitor resource usage and inform capacity planning.
- How does this differ from standard monitoring?Monitoring tells you if the system is broken; observability tells you why it is broken.
- Is this helpful for local startups?Even small teams benefit from observability as it prevents technical debt and speeds up feature development.
Final Thoughts: Is Master in Observability Engineering Worth It?
If you are an engineer or leader looking to move beyond simple uptime monitoring, this is an investment worth making. The industry is moving toward systems that are too complex to manage by hand; having the ability to instrument, visualize, and analyze those systems is a career-defining advantage. Do not treat this as just another certificate for your resume. Treat it as a toolkit that will change how you approach system design and incident response forever. The effort you put into mastering these principles will pay off in reduced stress, faster resolutions, and a more stable production environment for your team.